Come costruire un sistema stereoscopico integrato personalizzato per la percezione della profondità

Esistono diverse opzioni di sensori 3D per lo sviluppo di sistemi di percezione della profondità, tra cui la visione stereoscopica con telecamere, lidar e sensori a tempo di volo. Ogni opzione ha i suoi punti forti e i suoi punti deboli. Un sistema stereoscopico ha generalmente un costo ridotto, è abbastanza robusto per essere utilizzato all'aperto e può fornire una nuvola di punti di colore ad alta risoluzione.
Attualmente, sul mercato, sono disponibili vari sistemi stereoscopici pronti all'uso. A seconda di fattori quali precisione, linea di base, campo visivo e risoluzione, ci sono momenti in cui i tecnici del sistema devono creare un sistema personalizzato per soddisfare requisiti applicativi specifici.
In questo articolo vengono prima descritte le parti principali di un sistema di visione stereoscopica, quindi vengono fornite istruzioni su come realizzare la propria telecamera stereoscopica personalizzata utilizzando componenti hardware pronti all'uso e software open source. Poiché questa configurazione è incentrata sull'integrazione, calcolerà una mappa di profondità di qualsiasi scena in tempo reale, senza la necessità di un computer host. In un articolo separato viene illustrato come costruire un sistema stereoscopico personalizzato da utilizzare con un computer host quando lo spazio è meno vincolante.
Un’altra applicazione che può trarre grandi benefici da tale sistema di elaborazione integrato è il rilevamento degli oggetti. Con i progressi nel deep learning, è diventato relativamente facile aggiungere il rilevamento degli oggetti alle applicazioni, ma la necessità di risorse GPU dedicate lo rende proibitivo per molti utenti. In questo articolo, discutiamo anche di come aggiungere il deep learning a un’applicazione di visione stereoscopica senza la necessità di una costosa GPU host. Abbiamo suddiviso le sezioni e il codice di esempio di questo articolo in visione stereoscopica e deep learning, quindi se l’applicazione di interesse non richiede il deep learning, è possibile saltare le relative sezioni.
Panoramica della visione stereoscopica
La visione stereoscopica è l'estrazione di informazioni 3D da immagini digitali mediante il confronto delle informazioni in una scena da due punti di vista. Le posizioni relative di un oggetto in due piani immagine forniscono informazioni sulla profondità dell'oggetto dalla telecamera.
Una panoramica di un sistema di visione stereoscopica è riportata nella Figura 1. Il sistema richiede i seguenti passaggi chiave:
- Calibrazione: calibrazione della telecamera si riferisce sia alla calibrazione intrinseca che a quella estrinseca La calibrazione intrinseca determina il centro dell'immagine, la lunghezza focale e i parametri di distorsione, mentre quella estrinseca determina le posizioni 3D delle telecamere. Si tratta di un passaggio cruciale in molte applicazioni di visione computerizzata, specialmente quando sono richieste informazioni metriche sulla scena, come la profondità. La fase di calibrazione verrà discussa in dettaglio nella Sezione 5 riportata di seguito.
- Rettificazione: la rettificazione stereoscopica si riferisce al processo di riproduzione dei piani delle immagini su un piano comune parallelo alla linea tra i centri delle telecamere. Dopo la rettificazione, i punti corrispondenti si troveranno sulla stessa linea, il che ridurrà notevolmente i costi e l’ambiguità della corrispondenza. Questo passaggio viene eseguito nel codice fornito per la creazione del proprio sistema.
- Corrispondenza stereoscopica: si riferisce al processo di corrispondenza dei pixel tra le immagini a sinistra e destra e che genera immagini di disparità. L’algoritmo di corrispondenza semi-globale (Semi-Global Matching, SGM) sarà utilizzato nel codice fornito per costruire il proprio sistema.
- Triangolazione: la triangolazione si riferisce al processo di determinazione di un punto nello spazio 3D, data la sua proiezione sulle due immagini. L'immagine di disparità verrà convertita in una nuvola di punti 3D.
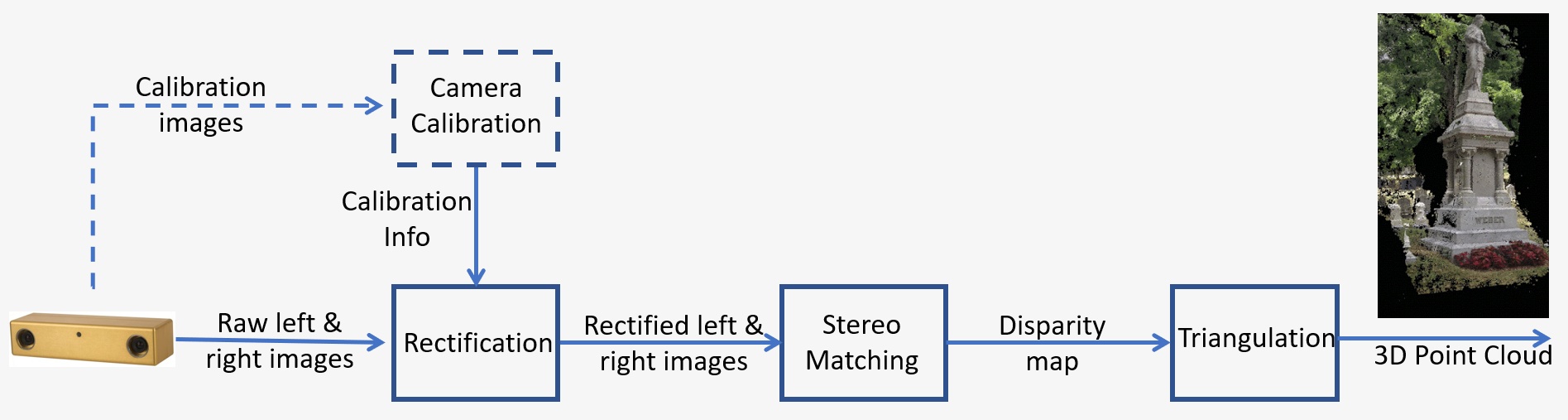
Figura 1: Panoramica di un sistema di visione stereoscopica
Panoramica del deep learning
Il deep learning è un sottocampo dell’apprendimento automatico che si occupa di algoritmi ispirati alla struttura e alla funzione del cervello. Cerca di imitare la capacità di apprendimento del cervello umano. Gli algoritmi di deep learning possono eseguire in maniera efficiente operazioni complesse, come il riconoscimento degli oggetti, la classificazione, la segmentazione, ecc. Tra le altre cose, il deep learning consente alle macchine di riconoscere persone e oggetti nelle immagini che gli vengono fornite. L’applicazione che ci interessa in questa sede è il rilevamento delle persone. L’addestramento degli algoritmi di deep learning richiede una grande quantità di dati di addestramento etichettati, ma i modelli open source pre-addestrati rendono più facile per chiunque sviluppare queste applicazioni.
Il deep learning richiede anche GPU ad alte prestazioni, ma la soluzione Quartet per TX2 viene fornita con tutte le funzionalità di una GPU più grande a una frazione del fattore di forma e del consumo energetico. Avere i modelli di deep learning in esecuzione sul TX2 ha anche l’ulteriore vantaggio della mobilità; il sistema è inoltre un candidato perfetto per i robot mobili che devono essere in grado di rilevare le persone per evitarle.
Esempio di progettazione
Di seguito è riportato un esempio di progettazione del sistema stereoscopico. Questi sono i requisiti per un’applicazione robotizzata mobile in un ambiente dinamico con oggetti in rapido movimento. La scena di interesse ha una dimensione di 2 m, la distanza dalle telecamere alla scena è di 3 m e la precisione desiderata è di 1 cm a 3 m.
Per ulteriori dettagli sulla precisione stereoscopica, fare riferimento a questo articolo. L'errore di profondità è dato da: ΔZ=Z²/Bf * Δd che dipende dai seguenti fattori:
- Z è l'intervallo
- B è la linea di base
- f è la lunghezza focale in pixel, correlata al campo visivo della telecamera e alla risoluzione dell'immagine
Ci sono varie opzioni di progettazione che possono soddisfare questi requisiti. In base alle dimensioni della scena e ai requisiti di distanza indicati sopra, è possibile determinare la lunghezza focale dell'obiettivo per un sensore specifico. Insieme alla linea di base, è possibile utilizzare la formula riportata sopra per calcolare l'errore di profondità previsto a 3 m e verificare che soddisfi i requisiti di precisione.
Nella Figura 2 sono mostrate due opzioni, in cui vengono utilizzate telecamere a risoluzione più bassa con una linea di base più lunga o telecamere a risoluzione più alta con una linea di base più corta. La prima opzione include una telecamera più grande, ma richiede una minore quantità di calcoli, mentre la seconda è una fotocamera più compatta, ma richiede una maggiore quantità di calcoli. Per questa applicazione, è stata scelta la seconda opzione in quanto una dimensione compatta è più desiderabile per il robot mobile ed è possibile utilizzare la soluzione integrata Quartet per TX2 che ha una potente GPU integrata per gestire le esigenze di elaborazione.

Figura 2: Opzioni di progettazione del sistema stereoscopico per un'applicazione di esempio
Requisiti hardware
Per questo esempio, vengono montate due telecamere Blackfly S su scheda da 1,6 MP utilizzando il sensore otturatore globale Sony Pregius IMX273 su una barra stampata 3D a una linea di base di 12 cm. Entrambe le telecamere hanno obiettivi simili da 6 mm con montaggio a S. Le telecamere si collegano al portaschede personalizzato della soluzione integrata Quartet per TX2 utilizzando due cavi FPC. Per sincronizzare le telecamere sinistra e destra e acquisire immagini contemporaneamente, viene creato un cavo di sincronizzazione che le collega. La Figura 3 mostra le viste anteriore e posteriore del sistema stereoscopico integrato personalizzato.

Figura 3: Viste anteriore e posteriore del sistema stereoscopico integrato personalizzato
Nella tabella seguente sono elencati tutti i componenti hardware:
|
Codice |
Descrizione |
Quantità |
Collegamento |
|
ACC-01-6005 |
Portaschede Quartet con modulo TX2 da 8 GB |
1 |
https://www.flir.com/products/quartet-embedded-solution-for-tx2/ |
|
BFS-U3-16S2C-BD2 |
1,6 MP, 226 FPS, Sony IMX273, a colori |
2 |
|
|
ACC-01-5009 |
Montaggio a S e filtro IR per telecamere a colori BFS su scheda |
2 |
|
|
BW3M60B-1000 |
Obiettivo con montaggio a S da 6 mm |
|
http://www.boowon.co.kr/site/ |
|
ACC-01-2401 |
Cavo FPC da 15 cm per Blackfly S su scheda |
2 |
https://www.flir.com/products/15-cm-fpc-cable-for-board-level-blackfly-s/ |
|
XHG302 |
Dissipatore di calore attivo NVIDIA® Jetson™ TX2/TX2 4GB/TX2i |
1 |
https://connecttech.com/product/nvidia-jetson-tx2-tx1-active-heat-sink/ |
|
Cavo di sincronizzazione (creare il proprio) |
1 |
||
|
Barra di montaggio (creare la propria) |
1 |
Entrambi gli obiettivi devono essere regolati per mettere a fuoco le telecamere sulla gamma di distanze richieste dall'applicazione. Serrare la vite (cerchiata in rosso nella Figura 4) su ciascun obiettivo per mantenere la messa a fuoco.

Figura 4: Vista laterale del sistema stereoscopico che mostra la vite dell'obiettivo
Requisiti del software
a. Spinnaker
L’SDK Spinnaker di Teledyne FLIR è preinstallato sulle soluzioni integrate Quartet per TX2. Spinnaker è necessario per comunicare con le telecamere.
b. OpenCV 4.5.2 con supporto CUDA
OpenCV versione 4.5.1 o successiva è richiesto per SGM, l'algoritmo di corrispondenza stereoscopico utilizzato. Scaricare il file zip contenente il codice per questo articolo e decomprimerlo nella cartella StereoDepth. Lo script per installare OpenCV è OpenCVInstaller.sh. Digitare i seguenti comandi in un terminale:
- cd ~/StereoDepth
- chmod +x OpenCVInstaller.sh
- ./OpenCVInstaller.sh
Il programma di installazione chiederà di inserire la password di amministrazione. Il programma di installazione inizierà a installare OpenCV 4.5.2. Il download e la creazione di OpenCV potrebbero richiedere un paio d'ore.
c. Jetson-inference (se è necessario il deep learning)
Jetson-inference è una libreria open source di NVIDIA che può essere utilizzata per il deep learning accelerato da GPU su dispositivi Jetson, come il TX2. La libreria utilizza l’SDK TensorRT, che facilita l’inferenza ad alte prestazioni sulle GPU NVIDIA. Jetson-inference fornisce all’utente una serie di modelli di deep learning pre-addestrati e pronti all’uso e il codice per distribuirli utilizzando TensorRT. Per installare Jetson-inference, digitare i seguenti comandi in un terminale:
- cd ~/StereoDepth
- chmod +x InferenceInstaller.sh
- ./InferenceInstaller.sh
Calibrazione
Il codice per acquisire immagini stereoscopiche e calibrarle è disponibile nella cartella “Calibration” (Calibrazione). Utilizzare l’interfaccia utente di SpinView per identificare i numeri di serie delle telecamere a sinistra e a destra. Per le nostre impostazioni, la telecamera destra è il master e la telecamera sinistra è lo slave. Copiare i numeri di serie delle telecamere master e slave nelle righe 60 e 61 del file grabStereoImages.cpp. Creare l’eseguibile utilizzando i seguenti comandi in un terminale:
- cd ~/StereoDepth/Calibration
- mkdir build
- mkdir -p images/{left, right}
- cd build
- cmake ..
- make
Stampare il motivo a scacchiera da questo collegamento e fissarlo a una superficie piana da utilizzare come destinazione di calibrazione. Per risultati ottimali durante la calibrazione, in SpinView impostare Exposure Auto (Esposizione automatica) su Off e regolare l’esposizione in modo che il pattern a scacchiera sia chiaro e i quadrati bianchi non siano sovraesposti, come mostrato nella Figura 5. Dopo aver acquisito le immagini di calibrazione, il guadagno e l’esposizione possono essere impostati su Auto (Automatico) in SpinView.
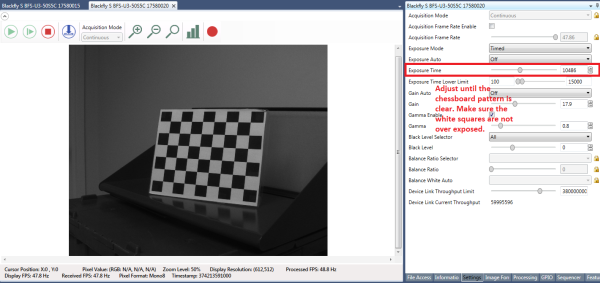
Figura 5: Impostazioni interfaccia utente SpinView
Per iniziare a raccogliere le immagini, digitare
- ./grabStereoImages
Il codice dovrebbe iniziare a raccogliere immagini a una velocità di circa 1 fotogramma al secondo. Le immagini a sinistra vengono memorizzate nella cartella immagini/sinistra mentre le immagini a destra nella cartella immagini/destra. Spostare la destinazione affinché appaia in ogni angolo dell'immagine. È possibile ruotare la destinazione, acquisire immagini da vicino e da lontano. Per impostazione predefinita, il programma acquisisce 100 coppie di immagini, ma questo comportamento può essere modificato con un argomento della riga di comando:
- ./grabStereoImages 20
In questo modo verranno raccolte solo 20 coppie di immagini. Si prega di notare che questo sovrascriverà tutte le immagini precedentemente memorizzate nelle cartelle. Alcune immagini di calibrazione dei campioni sono mostrate nella Figura 6.

Figura 6: Immagini di calibrazione dei campioni
Dopo aver raccolto le immagini, eseguire il codice Python di calibrazione digitando:
- cd ~/StereoDepth/Calibration
- python cameraCalibration.py
Questo genererà 2 file chiamati “intrinsics.yml” e “extrinsics.yml” che contengono i parametri intrinseci ed estrinseci del sistema stereoscopico. Per impostazione predefinita, il codice presuppone una dimensione quadrata della scacchiera di 30 mm, ma questa può essere modificata, se necessario. Al termine della calibrazione, verrà visualizzato l'errore RMS che indica il grado di efficacia della calibrazione. L'errore RMS tipico per una buona calibrazione deve essere inferiore a 0,5 pixel.
Mappa di profondità in tempo reale
Il codice per calcolare la disparità in tempo reale si trova nella cartella “Depth” (Profondità). Copiare i numeri di serie delle telecamere nelle righe 230 e 231 del file live_disparity.cpp. Creare l’eseguibile utilizzando i seguenti comandi in un terminale:
- cd ~/StereoDepth/Depth
- mkdir build
- cd build
- cmake ..
- make
Copiare i file “intrinsics.yml” e “extrinsics.yml” ottenuti nella fase di calibrazione in questa cartella. Per eseguire la demo della mappa di profondità in tempo reale, digitare
- ./live_disparity
Viene visualizzata l'immagine della telecamera sinistra (immagine grezza non rettificata) e la mappa di profondità (l’output finale). Alcuni output di esempio sono mostrati nella Figura 7. La distanza dalla telecamera è codificata a colori in base alla legenda a destra della mappa di profondità. La regione nera nella mappa di profondità indica che non sono stati trovati dati di disparità in quella regione. Grazie alla GPU NVIDIA Jetson TX2, è possibile eseguire fino a 5 fotogrammi al secondo con una risoluzione di 1440 × 1080 e fino a 13 fotogrammi al secondo con una risoluzione di 720 × 540.
Per vedere la profondità in un punto particolare, fare clic su quel punto nella mappa di profondità e verrà visualizzata la profondità, come mostrato nell'ultimo esempio nella Figura 7.

Figura 7: Esempio di immagini della telecamera sinistra e mappa di profondità corrispondente. La mappa di profondità inferiore mostra anche la profondità in un punto particolare.
Rilevamento di persone
Utilizziamo DetectNet, offerto da Jetson-inference, per rilevare gli esseri umani in un’inquadratura. DetectNet viene fornito con opzioni che consentono di selezionare l’architettura del modello di deep learning per il rilevamento degli oggetti. Impieghiamo l’architettura Single Shot Detection (SSD) con backbone MobileNetV2 per ottimizzare sia la velocità sia la precisione. Quando la demo viene eseguita per la prima volta, TensorRT crea un motore serializzato per ottimizzare ulteriormente la velocità di inferenza; il completamento di questa attività può richiedere alcuni minuti. Il motore viene automaticamente salvato in file per ulteriori esecuzioni. L’architettura utilizzata è piuttosto efficiente: la frequenza di cattura prevista per l’esecuzione del modulo di rilevamento è di circa 50 fps. Il codice per la funzionalità di rilevamento delle persone insieme alla profondità stereo in tempo reale si trova nella cartella “DepthAndDetection”. Copiare i numeri di serie delle telecamere nelle righe 271 e 272 del file live_disparity.cpp. Costruire l’eseguibile usando i seguenti comandi in un terminale:
- cd ~/StereoDepth/DepthAndDetection
mkdir
buildcd
buildcmake ..
make
Copiare in questa cartella i file “intrinsics.yml” e “extrinsics.yml” ottenuti nella fase di calibrazione. Per eseguire la demo della mappa di profondità in tempo reale, digitare
- ./live_disparity
Verranno visualizzate due finestre con le immagini a colori rettificate a sinistra e la mappa di profondità. La mappa di profondità è codificata a colori per una migliore visualizzazione. Entrambe le finestre hanno riquadri di delimitazione che circondano le persone nell’inquadratura e mostrano la distanza media della persona dalla telecamera. Con l’elaborazione stereo e l’inferenza di deep learning, la demo viene eseguita a circa ~4 fps con una risoluzione di 1440 × 1080 e fino a 11,5 fps con una risoluzione di
720 × 540.

Figura 1: Esempio di immagini della telecamera a sinistra e mappa di profondità corrispondente. Tutte le immagini mostrano la persona rilevata e la sua distanza dalla telecamera
L’algoritmo di rilevamento delle persone è in grado di rilevare più persone anche in condizioni difficili, come in caso di occlusione. Il codice calcola le distanze da tutte le persone rilevate nell’immagine, come mostrato di seguito.

Figura 2: L’immagine a sinistra e la mappa di profondità mostrano più persone rilevate nell’immagine e la corrispondente distanza dalla telecamera.
Sommario
L’uso della visione stereoscopica per sviluppare una percezione della profondità offre i vantaggi di lavorare bene all’aperto, la capacità di fornire una mappa di profondità ad alta risoluzione e molto accessibile con componenti pronti all’uso a costo contenuto. A seconda dei requisiti, sul mercato sono disponibili diversi sistemi stereoscopici pronti all'uso. Se è necessario sviluppare un sistema stereoscopico integrato personalizzato, si tratta di un compito relativamente semplice con le istruzioni fornite qui.
Articoli correlati
-
Sistemi integrati
Come costruire un sistema stereoscopico integrato personalizzato per la percezione della profondità
Leggi tutto -
 Sistemi integrati
Sistemi integrati
Telecamere in streaming 4x con portaschede di dimensioni ridotte: Prototipo veloce
Leggi la storia -
 Sistemi integrati
Sistemi integrati
Guida all'integrazione di telecamere board level
Leggi la storia